Adam Optimizer
2021. 10. 26. 15:22ㆍAI/Deep Learning
Adam Optimizer
Optimizer
- Loss Function의 결과값을 최소화하는 모델 파라미터를 찾는것
- 최적화 알고리즘
- Network가 빠르고 정확하게 학습하도록 도와줌

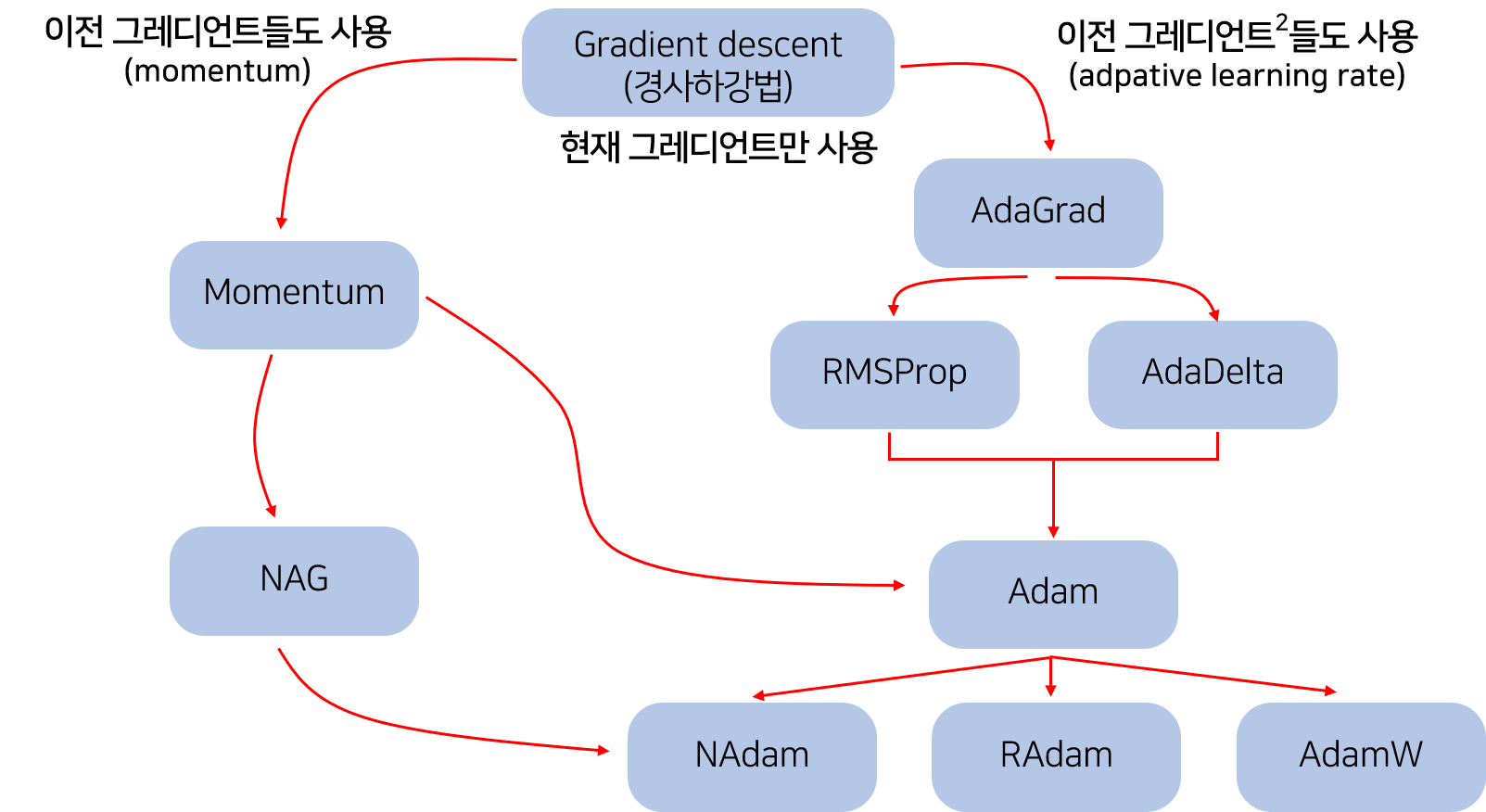
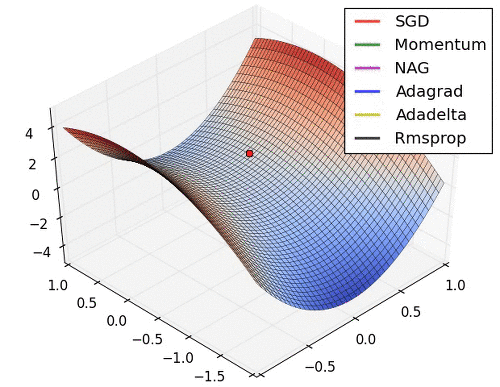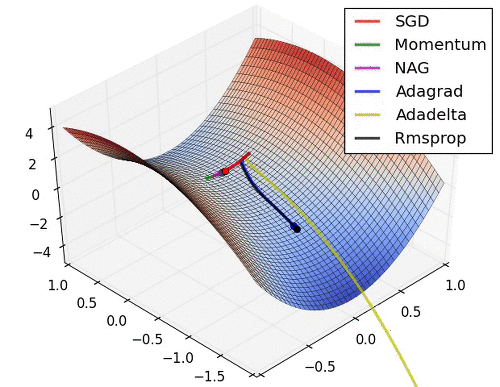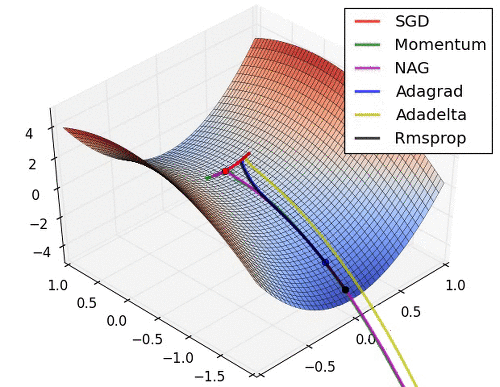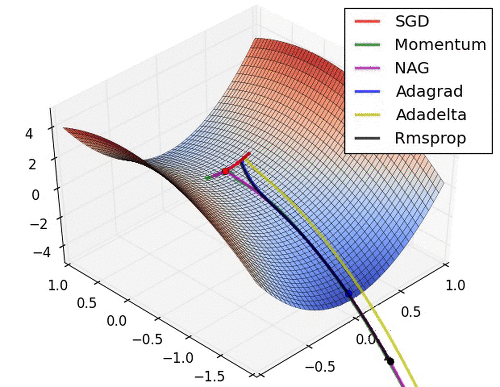
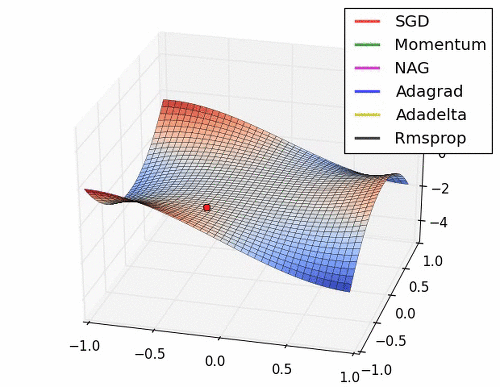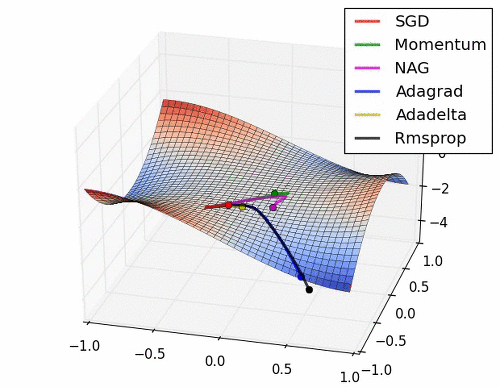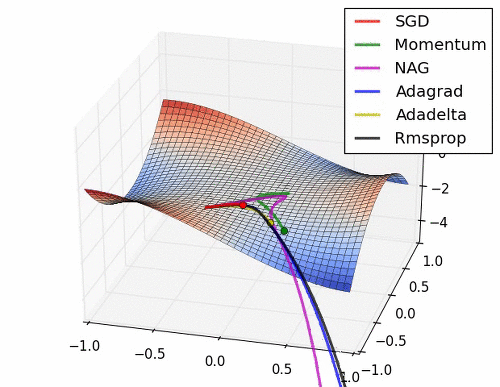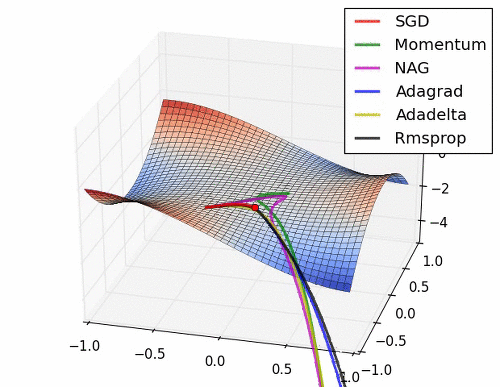

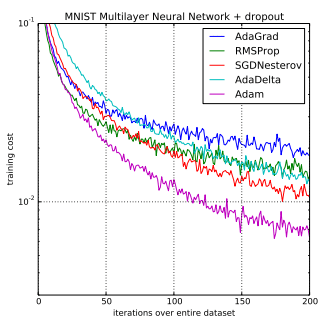
Background
Batch Gradient Descent
- 목적함수 f(θ)의 θ는 전체 훈련 데이터의 θ에 관한 f의 gradient를 기반으로 업데이트
- gt=∇θt−1f(θt−1)
- θt=θt−1−αgt
- α : learning rate
- t : t 번째 반복
- 주요 문제 : 목적함수의 local minima 또는 saddle point에 갇히는것
- 좋지 않은 수렴을 하게 만드는 learning rate의 선택
Stochastic Gradient Descent(SGD)
- gt=∇θt−1f(θt−1) 위와 같이 이 식으로 계산하고 파라미터를 업데이트하지만 트레이닝세트에서 각 트레이닝 샘플마다 반복
Mini-Batch Gradient Descent
- batch gradient descent와 stochastic gradient descent사이에서 mini-batch gradient descent 는 배치사이즈만큼의 트레이닝세트의 부분집합에서 gradient를 업데이트하는 파라미터를 계산
Adam(Adaptive Moment Estimation)
- gradient를 업데이트하는 첫 번째, 두 번째 moment를 추정하기 때문에 adaptive moment estimation에서 adam이 유래
- momentum을 가진 gradient descent(the first-order moment)와 RMSProp(the second-order moment)를 통합
- 지금까지 계산해온 기울기의 지수평균을 저장, 이동평균 & 가중평균 (Momentum)
- 기울기 제곱값의 지수평균을 저장, 이동가중평균(RMSProp)





- 논문 에서의 추천값 : β1=0.9, β2=0.999, ϵ=10−8
- m,v가 0으로 초기화 돼있어 0에 가깝게 bias 돼있을 것이라 판단해 이를 unbiased하게 만드는 작업을 거침
- library default
- TensorFlow: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08.
- Keras: lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0.
- Blocks: learning_rate=0.002, beta1=0.9, beta2=0.999, epsilon=1e-08, decay_factor=1.
- Lasagne: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- Caffe: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08
- MxNet: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
- Torch: learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8
Reference
https://onevision.tistory.com/category/Algorithm/Deep Learning
https://jjeongil.tistory.com/582
https://optimization.cbe.cornell.edu/index.php?title=Adam
http://shuuki4.github.io/deep learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
https://ruder.io/optimizing-gradient-descent/
https://towardsdatascience.com/understanding-adam-how-loss-functions-are-minimized-3a75d36ebdfc
https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
'AI > Deep Learning' 카테고리의 다른 글
| Federated Learning (0) | 2021.12.08 |
|---|---|
| Batch Normalization (0) | 2021.10.27 |
| Word2Vec (0) | 2021.10.25 |
| CNN(Convolutional Neural Network) (0) | 2021.10.22 |
| Dropout (0) | 2021.10.21 |